Hace poco encontrábamos en Rankia un artículo que trataba de explicar cómo funcionaban las redes neuronales no supervisadas, y concretamente los mapas auto-organizativos de Kohonen (SOM o self-organizing maps):
Parece útil su empleo en finanzas y como ejemplo vamos a simular la clasificación no supervisada de cuentas nómina de varias entidades financieras. Cuando se dispone de un gran número de casos (individuos o sujetos a comparar), y muchas variables para realizar la comparación, emplear redes neuronales no supervisadas como SOM ayuda a visualizar la información de manera ordenada y a la detección de patrones en los datos. Imaginemos que queremos comparar las siguientes cuentas nómina de varias entidades financieras:
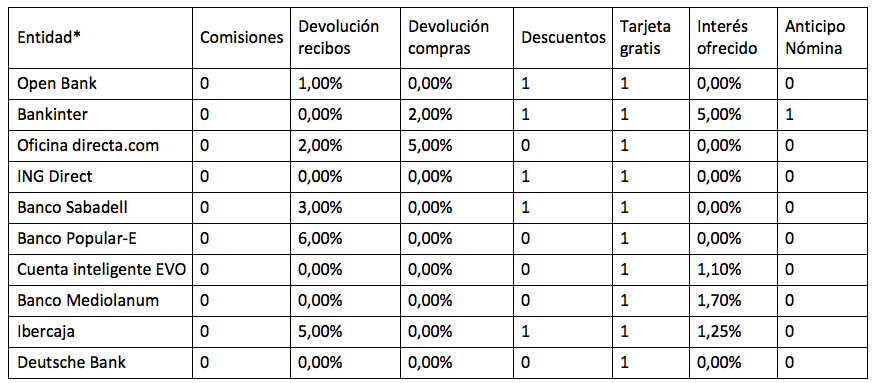
*La información representa ejemplos y, aunque se basan en casos reales, no reflejan todas las características ofrecidas por las entidades financieras. No se pretende en todo caso perjudicar ni publicitar a ninguna de las entidades financieras.
Comparar estas cuentas nómina puede ser fácil a simple vista pero sirven para ilustrar la utilidad de este tipo de redes (ha sido también aplicado a grandes cantidades de datos como clasificación de fondos de inversión o acciones). Como puede verse en la tabla ninguna de las cuentas presenta comisiones y todas ofrecen tarjetas de manera gratuita. Por este motivo pueden ser excluidas estas dos variables de nuestro modelo. Recordemos que una red de tipo SOM presenta este aspecto:

Hay un vector de entradas (input vector), que en nuestro caso son los datos de cada cuenta nómina y que serán clasificadas en un mapa de neuronas de tamaño X (SizeX) por Y (SizeY). La red empieza a entrenarse con pesos aleatorios (wij) y se le van presentando los datos para ir entrenándola. La red va identificando que neurona o grupo de neuronas son las más parecidas a los datos de entrada. Estas neuronas son las “ganadoras” y la red actualizará sus pesos para que ante otro patrón similar esas mismas neuronas estén más especializadas. Cuando el número de casos presentados a la red y el número de iteraciones que se llevan a cabo es lo suficientemente grande, los pesos acaban convergiendo y la red identificará la nueva información clasificándola en zonas dentro del mapa. Como disponemos de muy pocos datos el tamaño del mapa será muy pequeño. El resultado es el siguiente:

En este tipo de mapas las distancias son importantes y guardan relación con las distancias o diferencias de los datos de entrada. Así, las cuentas de Ibercaja y Popular-E son muy parecidas y bastantes diferentes de las cuentas nómina de ING y Deutsche Bank. Si nos fijamos en los datos vemos como las dos primeras se caracterizan por la devolución de los recibos del cliente a un tipo elevado, mientras que las dos últimas ofrecen menos servicios diferenciadores con relación al resto. Se pueden obtener las medias de cada variable en cada grupo y así determinar de manera sencilla que características tienen las celdas del mapa.
Ivan Pastor
Licenciado en Administración y Dirección de empresas y Máster en Banca y Finanzas en el Centro de Estudios Garrigues en Madrid.
Actualmente, terminando la tesis en la que precisamente empleo redes neuronales para la detección
y prevención de quiebras bancarias y la detección de desequilibrios macroeconómicos.
2


