La teoría Dow, la aleatoriedad y mi forma de extraer tendencias primarias
Voy a exponer mi punto de vista sobre la teoría de Dow y el estudio que he hecho sobre el DJIA (Dow Jones Industrial Average) desde 1930.
Llevo mucho tiempo dándole vueltas a todo lo que rodea al análisis técnico, estudiando y verificándolo. Y cuanto más ahondo en él, más componente aleatoria encuentro, y eso hace que me vaya haciendo cada vez más escéptico respecto a la posibilidad de ganar dinero simplemente basándome en gráficos. La única forma que veo de ganar dinero es basándose en información que no esté reflejada en los gráficos. Y eso solo se consigue de tres posibles formas, (a) estudiando el subyacente, (b) con experiencia, (c) con información privilegiada. La primera forma requiere calma, mucho tiempo y algo de inteligencia, la segunda requiere energía y valor para asumir la ruina más de una vez, y la tercera es ilegal. Yo por mi parte prefiero la primera, más por mi carácter que por otra cosa.
Lo primero que dice Dow es que en el precio está todo reflejado. Puede que sea cierto, pero precisamente por eso el precio no nos sirve para operar, porque en una única variable tenemos todo reflejado. Y aunque tengamos la ilusión de tener toda la información, en realidad no tenemos nada útil. Ya hablé de ello en el anterior post.
Pero eso no quiere decir que el gráfico del precio no podamos aprovecharlo. Podemos conocer la tendencia del mercado. Con la tendencia y la información del volumen que la acompaña, por ejemplo con el gráfico de acumulación-distribución, tenemos algo de información para hacernos una foto global del marco en el que nos movemos.
Un problema muy importante de cualquier gráfico de precio es la aleatoriedad. Y es muy importante por dos motivos:
- Puede por sí misma crear una tendencia fantasma.
- Si operamos bajo movimientos aleatorios perderemos siempre dinero.
Lo primero que he hecho es estudiar la componente aleatoria del DJIA. Para ello obtenemos la variable diferencia respecto al cierre anterior, como DIFERENCIA(i) = ( CIERRE(i) – CIERRE(i-1) ) / CIERRE(i-1)
Si la estudiamos veremos que cumple con una distribución estadística t de Student no estandarizada, con parámetros:
mu : 0.00041726
sigma : 0.00648176
nu : 2.66156875
Y se pueden crear tendencias fantasmas simplemente por esa componente estadística. Si operamos basándonos en ella pensando que es real acabaremos perdiendo dinero. Por ejemplo, la siguiente gráfica es una serie temporal aleatoria basada en la distribución estadística anterior. Y es 100% aleatoria:
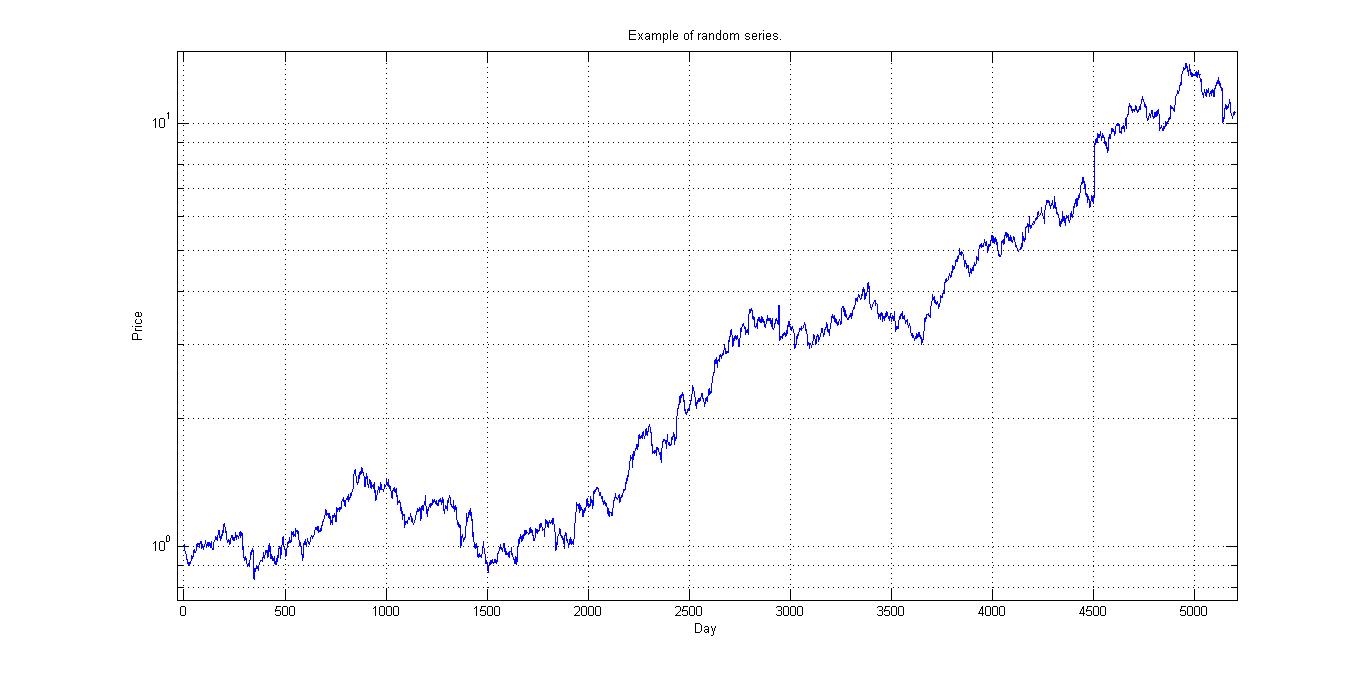
Si quieres generar series temporales aleatorias con la estadística del DJIA no tienes más que ejecutar estos comandos en matlab:
n = 260 ;
mu = 0.00042 ;
sigma = 0.0065 ;
nu = 2.7 ;
dift = trnd(nu,20*n,1)*sigma+mu;
seriest = ones(length(dift)+1,1) ;
for i=1:length(dift)
seriest(i+1) = seriest(i) * (1+dift(i)) ;
end
close all
semilogy(seriest)
grid on , xlabel('Day') , ylabel('Price') , title('Example of random series.')
El hecho de que tenga una media mayor que cero significa que las probabilidades de que las tendencias sean alcistas son mayores a que sean bajistas. No es que tenga ningún sentido por sí mismo, simplemente que la historia ha sido así, con mayores tendencias alcistas que bajistas.
Yo defino una tendencia como una serie con poca volatilidad, es decir, con un rango muy estrecho en un gráfico logarítmico. Y con una duración de al menos un año. Si estudiamos la estadística de los rangos de series temporales aleatorias generadas de la forma anterior vemos que se ajustan a una distribución normal logarítmica con parámetros:
mu : -1.57234694
sigma : 0.30058623
mean : 0.21714914
variance : 0.00445884
Los movimientos anuales con mayor probabilidad de ocurrencia son aquellos con un rango del 21.7% respecto a la regresión. Esto no son tendencias como las entendemos, suaves y lineales en gráfica logarítmica. Yo asumo como tendencias a aquellas que tienen una probabilidad de ocurrencia menor al 10%, y a estas les corresponde un rango del 14% que es un rango bastante estrecho. La aleatoriedad puede crear tendencias pero no es algo con alta probabilidad.
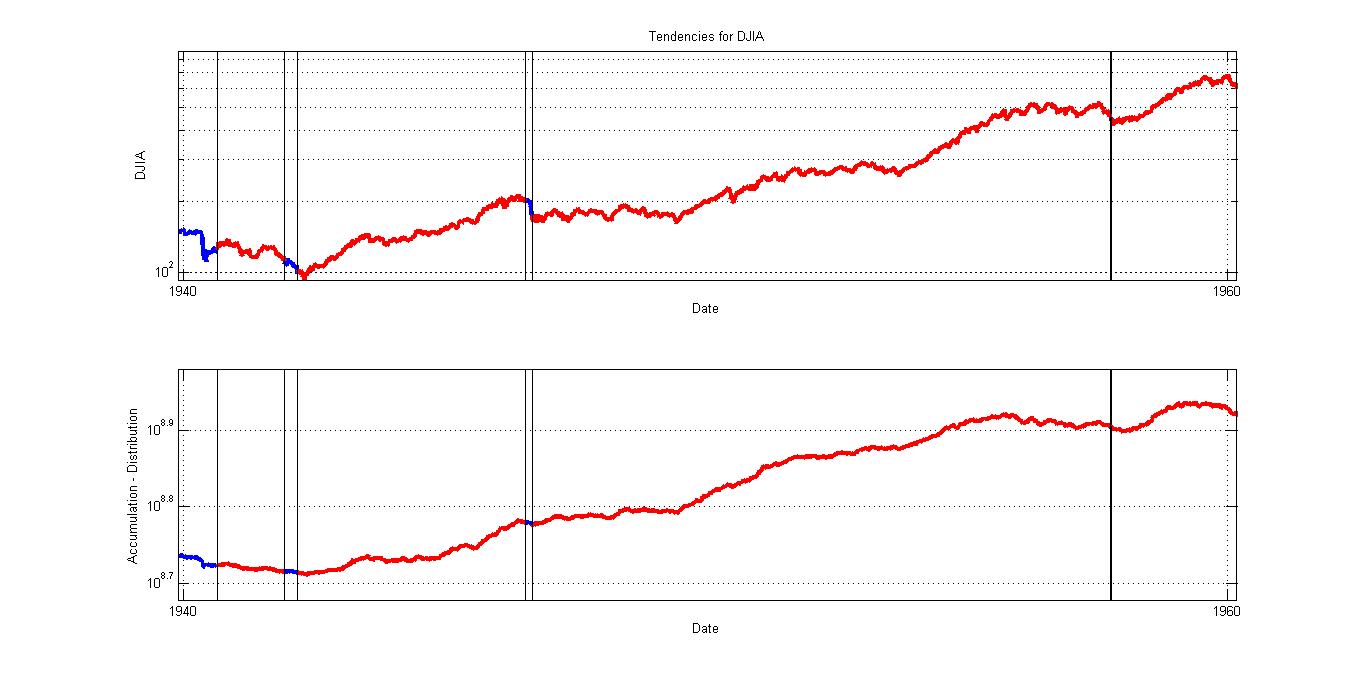
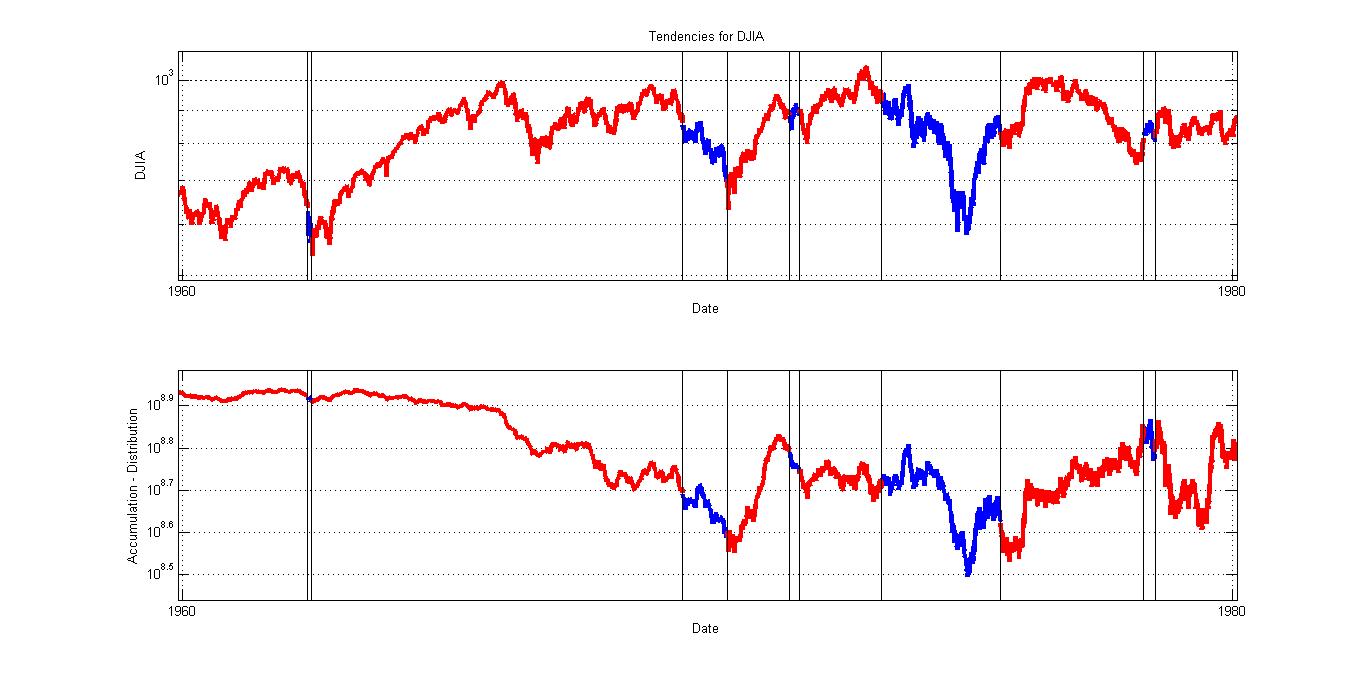
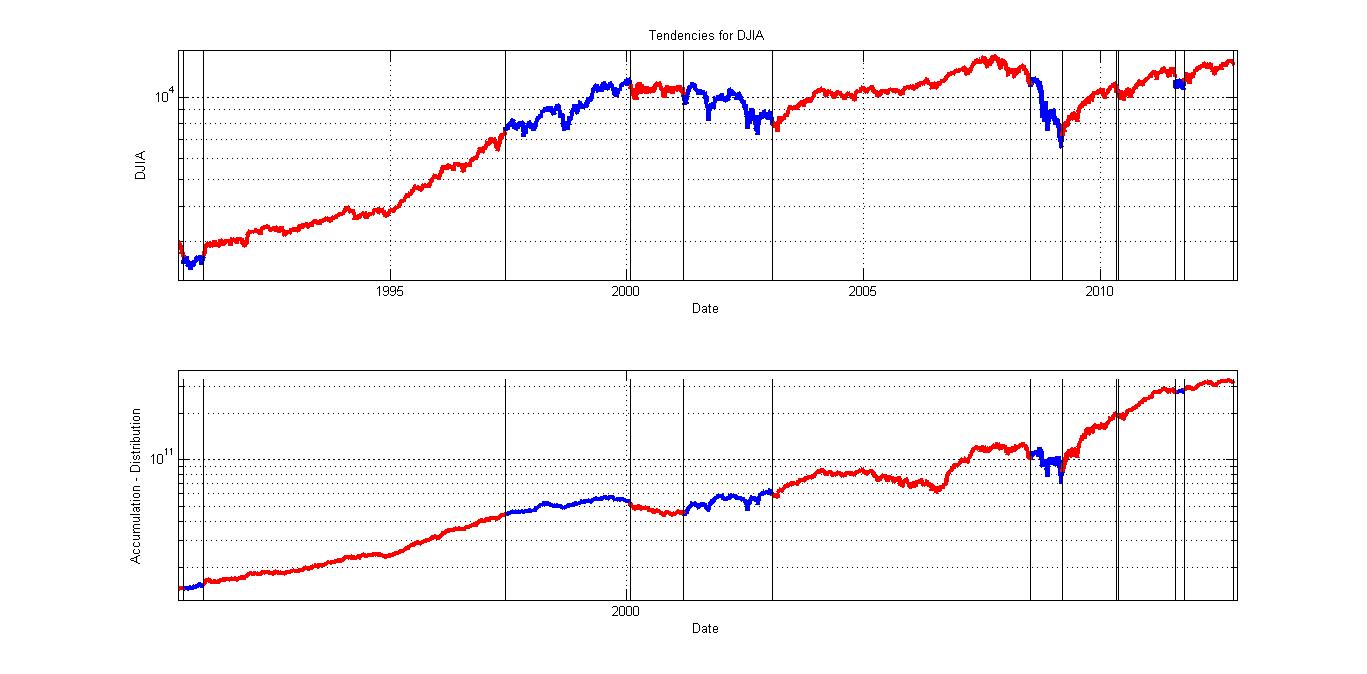
Sabiendo esto, estudio toda la serie temporal del DJIA desde 1930 y asumo que existe tendencia en el día x si la serie de un año hasta el día x tiene un rango menor a ese 14%. Y a eso yo lo llamo tendencia primaria.
Las conclusiones útiles que se pueden sacar son estas:
- Una tendencia con poca o media volatilidad acompañada por el gráfico acumulación-distribución es un movimiento natural. La causa es el interés creciente lineal, decreciente lineal o constante por el papel, y la consecuencia es la tendencia. Por ejemplo desde 1940 a 1960.
- Si una tendencia con poca volatilidad tiene divergencia con el gráfico acumulación-distribución puede que no sea ni un movimiento natural ni aleatorio, porque no tiene un origen natural y tiene baja probabilidad. Puede que alguien la esté guiando. Por ejemplo de 1965 a 1969, o de 2006 a 2008.
- Si una aparente tendencia tiene mucha volatilidad, es decir rangos amplios, no es tendencia porque tiene mucha probabilidad de ocurrencia, simplemente son movimientos aleatorios. Y ahí no se debe operar. Por ejemplo de 1997 a 2000 o en 1975.
Aquí pego algunas gráficas. En rojo están dibujadas las tendencias, en azul los movimientos con alta volatilidad.